 Batch processing is an important capability for a data translation and transformation tool like FME. So when we implement new functionality and somehow forget to give it much coverage… well my only excuse is that by my estimate each FME release has over twenty person-years work put into it, and it’s hard to fit all of that into a one-hour webinar!
Batch processing is an important capability for a data translation and transformation tool like FME. So when we implement new functionality and somehow forget to give it much coverage… well my only excuse is that by my estimate each FME release has over twenty person-years work put into it, and it’s hard to fit all of that into a one-hour webinar!
The forgotten update in this case is a new parameter in the WorkspaceRunner transformer. While it’s easy to miss, with the right handling and in the right scenario, it can really make FME batch processing fly at lightspeed.
Before I explain this new parameter, let’s just cover the WorkspaceRunner transformer, what it does, and how…
![]()
The WorkspaceRunner: What It Does
The WorkspaceRunner is simply a transformer whose action is to execute a second workspace:
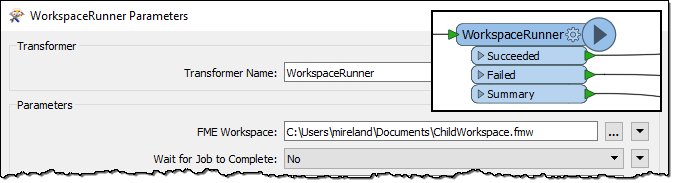
It’s a great tool for chaining a number of workspaces together. Workspace A runs, then calls Workspace B, which runs and then calls Workspace C, and so on. The WorkspaceRunner even lets you pass values to published parameters in the next workspace in the chain. This is useful for a number of scenarios, which we don’t need to go into now.
That’s because we’re more interested in the parameter it has for starting multiple processes:
It’s this Concurrent Processes parameter that makes the transformer superb for Batch Processing, as we can see in this example…
![]()
The WorkspaceRunner: A Batch Processing Example
Let’s say I have a folder of files that I wish to transform and then upload to a database. Here I’ll read from Shapefile format and write to PostGIS. I could just read all the source data, transform it, and send it to a database within a single FME workspace like so:
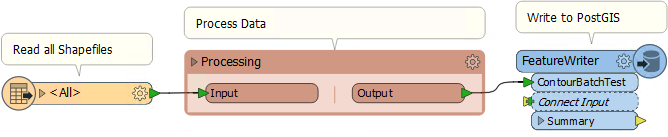
But trying to handle all of the source data simultaneously has obvious drawbacks, which is why we prefer to apply Batch Processing using the WorkspaceRunner transformer. This transformer permits batch processing because it can start the above workspace a number of times, processing a different dataset each time. Using the Concurrent Processes parameter there can even be a number of processes running in parallel (one per CPU core is optimum).
The setup is a “parent-child” arrangement. Here is the parent workspace that reads the names of Shapefiles in a folder (using the lesser-known Directory and File Pathnames reader) and passes that information into a WorkspaceRunner:
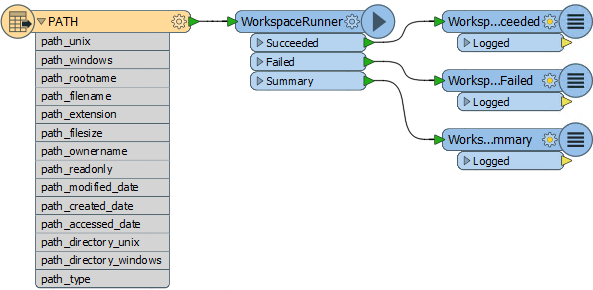
The WorkspaceRunner transformer starts the child workspace (the same as shown above) and passes the name of the Shapefile to read using a published parameter:
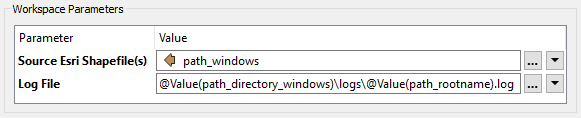
It even has a published parameter to allow the log file to be set using the Shapefile name, so we get a separate log per child process.
On my computer, if the WorkspaceRunner is set to use four concurrent processes the master workspace runs in three minutes:
Translation was SUCCESSFUL with 0 warning(s) (0 feature(s) output) FME Session Duration: 3 minutes 28.3 seconds. (CPU: 1.3s user, 1.4s system) END - ProcessID: 3616, peak process memory usage: 39496 kB, current process memory usage: 39488 kB Translation was SUCCESSFUL
This isn’t always the total time because the child workspaces may still be running. If I look at the child logs, I see:
First Workspace Starts: 2018-03-22 07:52:38 Final Workspace Ends: 2018-03-22 07:56:07
So a total of three minutes and 29 seconds, which seems pretty good.
However, this technique is not always good for small jobs, where the child workspace only takes a second or two to run. That’s because each run is a separate initiation of an FME process:
WorkspaceRunner: Running FME with command line - `{C:/Program Files/FME/fme}
WorkspaceRunner: Successfully initiated batch run of workspace `C:/Users/mireland/Documents/ChildWorkspace.fmw'
It takes time to start and stop each new FME process, and for small translations it can actually take longer to start the child workspace than to run it!
So that’s why we created a new parameter in FME2018…
![]()
WorkspaceRunner 2018: The New Parameter
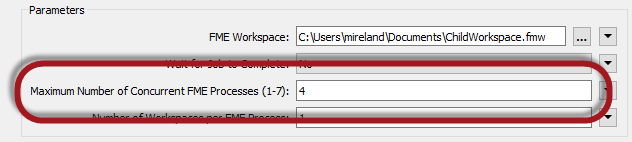
The 2018 WorkspaceRunner has a new parameter called Number of Workspaces per FME Process (that I sneakily hid in the earlier screenshot):
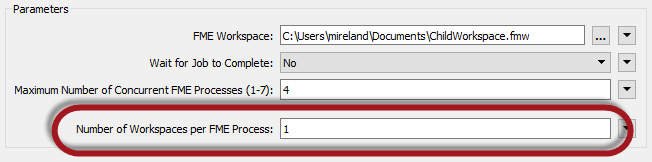
That parameter allows me to assign multiple child workspaces to a single process. For example, if I set it to 5 then each process would handle five child workspaces before it stopped and a new process started.
In my example I have 80 Shapefile files to read. With four processes I can say that is 20 files per process. That way I’ll only ever start four processes! No more stop/start at all.
So with the parameter set to 20, this time the master log tells me:
Translation was SUCCESSFUL with 0 warning(s) (0 feature(s) output) FME Session Duration: 5.7 seconds. (CPU: 0.1s user, 0.1s system) END - ProcessID: 2812, peak process memory usage: 39136 kB, current process memory usage: 39136 kB Translation was SUCCESSFUL
Now, obviously the whole process hasn’t finished in five seconds, that was just the time taken to start the child processes. Those processes are still running and this time each has more work to do. Still, the child logs show:
First Workspace Starts: 2018-03-22 07:33:42 Final Workspace Ends: 2018-03-22 07:35:35
That’s a total of one minute and 53 seconds, which is much better than before. That’s because we started only four processes, instead of 80.
Do the math(s) and you’ll see that the previous example took 1.25 seconds to start/stop each process, time that we’ve now saved.
When To Use
Obviously 1.25 seconds is not a huge amount if, for example, each child process was taking 10 minutes to run. In that scenario the start/stop time wouldn’t be much of an overhead.
But it’s a huge overhead when your child workspace is doing something very simple, like sending a geocoding request:
When I run this with a WorkspaceRunner sending one address at a time to geocode, it runs at 19 features per minute, totaling nearly 12 hours with the number of features I have. That’s even using four parallel processes!
But if I use the Workspaces per Process parameter, the rate becomes 225 per minute! This cuts my processing time down to just one hour! Maybe my “lightspeed” title is a bit excessive, but still… twelve times faster is pretty amazing as far as I’m concerned.
The lesson is that this parameter is most useful when you have many small jobs, instead of few large jobs.
But there are some other aspects to take into consideration…
![]()
The WorkspaceRunner: Considerations and Limitations
The primary consideration I see is the number of workspaces allowed per process. If – in my Shapefile example – I set the parameter to 80 then I’d get a single process handling all 80 jobs, which I think invalidates the whole batch processing concept!
So the Workspaces per Process setting should not be higher than jobs ÷ processes (for example 80 jobs ÷ 4 processes = 20).
Should it be less? Well you might – like me – worry that too many child workspaces executed by the same process might overload that process with data; i.e. the data accumulates. Thankfully that doesn’t seem to be the case. Experimenting showed that each process peaked at approximately the same level regardless of whether the parameter was set to 20 or 10.
![]()
But I still worried and so tested having one large dataset at the start of the batch. One process did increase in size as expected (PID4784 above), but as the data was written to the database that memory was released. It didn’t (as I worried) keep that memory for the duration of the batch processing.
So my worrying on your behalf was needless. It seems that the ideal value is exactly jobs ÷ processes. Of course you need to know in advance how many jobs are going to be created. If you don’t then you’d have to estimate because the Workspaces/Process parameter doesn’t allow you to use an attribute. I think I’ll file an enhancement request for that, where the first feature sets the parameter.
But I still think you need to know your datasets, and their size and composition, plus what transformers are used. My geocoding example was small in scale and wrote no output data, so that it actually ran faster without batching! So you must still consider whether batching is necessary at all.
Limitations
One limitation is that it’s harder to tell when processing has finished, since the parent workspace finishes well before its children. If it’s important then check the task manager to see if FME is still running. But it does mean the master workspace is released quicker and can be used to work on another task.
The second limitation that I found, is that simultaneous processes can lock each other out of writing to the same file. So if each process adds to the same dataset (as Geodatabase, GeoPackage, or Excel might do, for example) then one process can sometimes find itself locked out of the dataset by another:
WARN |Geodatabase Error (-2147220975): File read/write error occurred. WARN |FileGDB Writer: Could not set Write Lock for feature type 'Contours'. Write performance may be degraded WARN |Geodatabase Error (-2147220975): File read/write error occurred. WARN |FileGDB Writer: A feature could not be written
Of course this doesn’t apply to writing separate files or datasets, nor to databases that control their own locking. For example I was able to write to PostGIS with no problem at all.
![]()
The WorkspaceRunner: Conclusion
I’m not sure how we missed giving this more attention in the 2018 release presentations. But I do notice that Dale previewed it in one of the 2017 Back to School webinars (about 37 minutes in), so it was there all along if you knew where to look!
I hope that if you use the WorkspaceRunner transformer in FME, you’ll find this useful. Or if you haven’t tried the WorkspaceRunner for batch processing, do give it a try. There’s a good example on the knowledgebase and the fine folk on the FME Q+A forum are always there to assist.


Mark Ireland
Mark, aka iMark, is the FME Evangelist (est. 2004) and has a passion for FME Training. He likes being able to help people understand and use technology in new and interesting ways. One of his other passions is football (aka. Soccer). He likes both technology and soccer so much that he wrote an article about the two together! Who would’ve thought? (Answer: iMark)



