
Inner Join? Is that the opposite of an Outer Join?
When I was interviewed for a job with the team at Safe Software, one question asked was “Do you know the difference between a left join and an inner join?”
Although I’d used SQL and joins quite a lot before, I couldn’t remember the exact definition and mumbled an answer. I was hired, so the response must have been more convincing than I thought. Either that or they really liked my joke about the cinnamon buns.
The thing is, because I’ve had access to FME, I’ve rarely since needed to do SQL joins; so my knowledge of left and inner joins has remained a bit sketchy… until today!
Because today is when I started to try out the latest transformer to hit the Filters and Joins category: The FeatureJoiner.
![]()
What is the FeatureJoiner?
So the FeatureJoiner is a transformer that joins data together. It most closely resembles the FeatureMerger (which it may eventually replace). Here it is on the canvas:
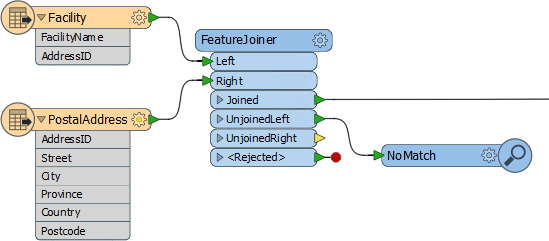
This workspace joins Facility features with PostalAddress records. You can see that instead of Requestor/Supplier the transformer has Left/Right ports, and one fewer output port; but otherwise it really does look like the FeatureMerger.
However, a look at the parameters dialog shows a lot more differences:
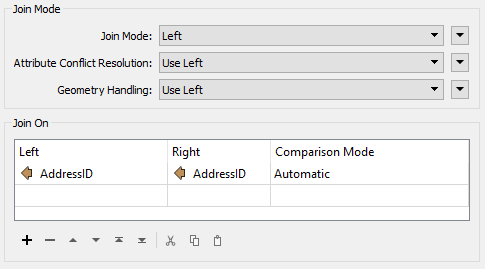
The Join On, Conflict Resolution, and Geometry Handling parameters are fairly obvious, and are similar to those that already exist in the FeatureMerger. But the key parameter is Join Mode…
![]()
Join Modes
The Join Mode is where it becomes necessary to know about Left Joins and Inner Joins. That’s because the three modes are Left Join, Inner Join, and Full Join.
For our training materials I made up a table that shows what these modes do:
| Mode | Description | Depiction | Joined Output | Unjoined Left | Unjoined Right |
|---|---|---|---|---|---|
| Left | Left features look for a match and are output whether they find a match or not | 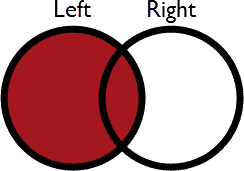 |
All matches plus unmatched Left features | None | Unused Right features |
| Inner | Left features look for a match and are output if they find one | 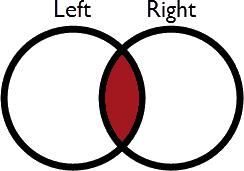 |
All matches only | Unmatched Left features | Unused Right features |
| Full | Both Left and Right features output through the Joined output port, whether they find a join or not | 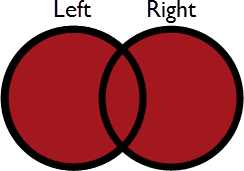 |
All matches plus unmatched Left and Right features | None | None |
The simplest way to understand the operation is this: the overlapping part in each diagram is always output. It’s a join so the features are output through the Joined port.
The Left/Inner/Full parameter controls not the joined features, but the features that aren’t joined.
- In Inner mode features without a join exit through either the Unjoined Left or Unjoined Right port.
- In Left mode, Left features without a match still exit through the Joined port. Right features without a match exit the Unjoined Right port.
- In Full mode, both Left and Right features without a match still exit through the Joined port.
The Facility Example
So, remember our Facility/Address example, which matches Facility features to Address records:
In Inner mode, only facilities with a matching address exit through the Joined port. It’s a good way to find non-matching features, which exit through the Unjoined Left port.
But in Left mode, all facilities exit the Joined port, whether they have a match or not. It’s not so good for data QA, but it’s fine if we know not every facility has a matching address.
In Full mode, the Joined output would include ALL addresses, used or not. It’s probably not needed in this case, but it is useful in other scenarios.
Now, you may have noticed that the FeatureJoiner has no equivalent to the FeatureMerger “handle duplicate suppliers” parameter. To understand that you need to understand what we mean by a “match”…
![]()
Multiple Join Matches
To understand this, let’s take a look at this with some feature count numbers included:
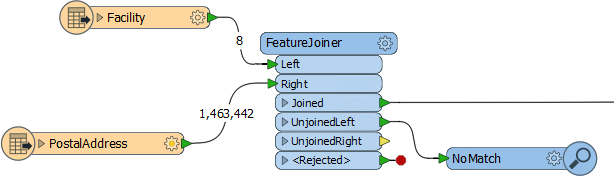
How many features will exit the Joined port? Well, it depends.
If we assume a strict 1:1 match between each Facility and an Address, then 8 features will exit as Joined. Why? Because we have 8 matches. The count will be thus:
| Mode | Joined | Unjoined Left | Unjoined Right |
|---|---|---|---|
| Left | 8 | 0 | 1,463,434 |
| Inner | 8 | 0 | 1,463,434 |
| Full | 1,463,442 | 0 | 0 |
The Full Joined number of 1,463,442 consists of 8 matches and 1,463,434 unmatched right features.
So that’s good. However, we might not have such a clean 1:1 match between Facility and Address table. We could have 1:M, M:1, or even M:M.
Let’s say each Facility has two matches in the Address table. Then we get this:
| Mode | Joined | Unjoined Left | Unjoined Right |
|---|---|---|---|
| Left | 16 | 0 | 1,463,426 |
| Inner | 16 | 0 | 1,463,426 |
| Full | 1,463,442 | 0 | 0 |
Why are we getting more features out than we put into the Left port? Because we are getting one feature per match, and there are 16 matches!
This is not something the FeatureMerger would do. It would either ignore the second match or create a list. But this is designed to be a SQL equivalent, and so it works differently. In fact – in an extreme case – if we assumed that every Facility has AddressID=1, and every Address has AddressID=1, then every facility would match to every address!
That would give us 8 x 1,463,442 = 11,707,536 matches!
To put it another way, in Left or Inner mode we could put in 8 “requestor” features and get out 11,707,536. It’s not wrong, just perhaps different than what you’re used to.
Output Order
As a bit of an advanced topic, matches exit the the transformer in the same order as the features enter the Left port.
So if the Left features are sorted in a particular order when they enter the transformer, that order is unchanged in the output, for either a Left or Inner join.
If you want to retain the input order for a Full join, then both the Left and Right inputs must be already sorted in order.
![]()
Which to Use?
So which transformer should you be using? Well there are two aspects to consider: functionality and performance.
For functionality the FeatureJoiner is certainly nicer for users used to database terminology and functionality. It’s designed to mimic SQL so the results should be the same as if you’d entered the same SQL join commands.
 The key output difference is the one-feature-per-match concept of the FeatureJoiner. The FeatureMerger would let you create a list instead. But I’d say that a lot of the time you immediately use a ListExploder to break the list up into features anyway, so I’m not sure how much disadvantage it is to not have a List parameter in the FeatureJoiner.
The key output difference is the one-feature-per-match concept of the FeatureJoiner. The FeatureMerger would let you create a list instead. But I’d say that a lot of the time you immediately use a ListExploder to break the list up into features anyway, so I’m not sure how much disadvantage it is to not have a List parameter in the FeatureJoiner.
Plus, if you really need a list, follow up with a ListBuilder grouping by your join keys. This is where output order is important, as you might be able to set Input Ordered by Group in the ListBuilder, if the FeatureJoiner input was suitably sorted.
As for performance, the FeatureJoiner boasts an improved design, and gets an added boost by using the “Feature Table” technology that speeds up so many other readers, writers, and transformers. So if performance is important then you should definitely try out the FeatureJoiner.
![]()
Summary
You may be more comfortable sticking with the familiar FeatureMerger at first, but it’s worth going out of your comfort zone to at least try the FeatureJoiner.
You might even learn some terminology to help land your dream job!
As an example of the improved performance, check out the video of the FME 2018 unveiling:

There (jump to 58 minutes if it doesn’t automatically) Don and Dale carry out a left join on a CSV file of 320,000 records. The workspace takes 53 seconds to complete with the Joiner and 5 minutes, 33 seconds to complete with the FeatureMerger. So performance improves greatly in that example.
Incidentally, notice in the video that their transformer’s name is the Joiner. We’ve since changed it to FeatureJoiner, to be less confusing (given that there used to be a Joiner, which is now the DatabaseJoiner). I believe Joiner is still an alias for the DatabaseJoiner, but “DJ” or “FJ” in Quick Add bring up these transformers quicker anyway!
Additionally, if you want to carry out joins, don’t forget the InlineQuerier transformer. It constructs an ad hoc database and allows you to carry out SQL commands on it – so if your join is more complex than the FeatureJoiner/Merger allow, try the InlineQuerier instead.

NB: If you are looking for a job(!) follow FMEJobs on Twitter, or check out the Safe Software careers page – and don’t forget to brush up on joins before your interview!

Mark Ireland
Mark, aka iMark, is the FME Evangelist (est. 2004) and has a passion for FME Training. He likes being able to help people understand and use technology in new and interesting ways. One of his other passions is football (aka. Soccer). He likes both technology and soccer so much that he wrote an article about the two together! Who would’ve thought? (Answer: iMark)



